1. 스태킹(Stacking)의 핵심 개념
스태킹은 여러 가지 모델들의 예측값을 최종 모델의 학습 데이터로 사용하는 예측하는 방법 입니다.
아직 잘 와닿지가 않나요?
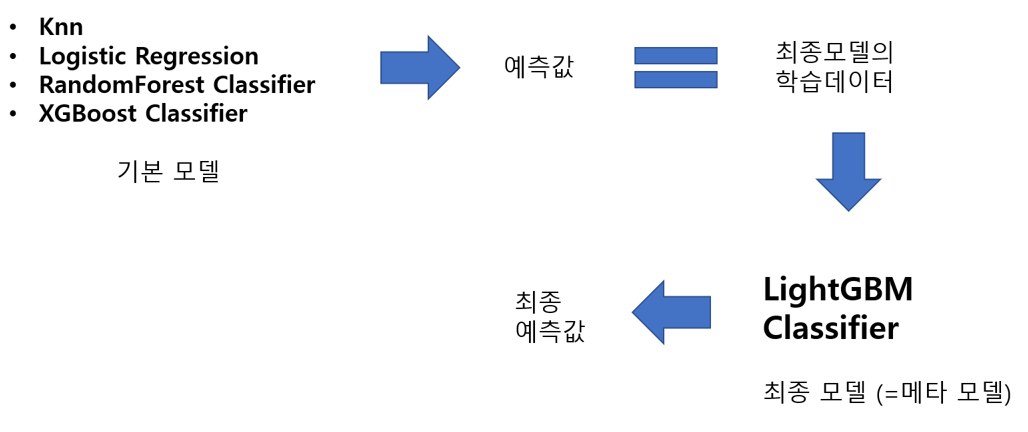
간단한 예시를 아래 그림과 함께 들어보겠습니다.
저는 knn, logistic regression, randomforest, xgboost 모델을 이용해서 4종류의 예측값을 구했습니다.
그리고 이 예측값을 하나의 데이터 프레임으로 만들어 최종모델인 lightgbm의 학습데이터로 사용했습니다.
지금은 기본 모델로부터 예측된 값들이 최종모델의 학습데이터로 사용된다는 것만 이해하면 됩니다.
자세한 내용은 다음 절에서 다루겠습니다.
 스태킹 예시
스태킹 예시
이렇게 하면 성능이 무조건 좋아지냐?
그건 아닙니다. 현실 모델에서도 많이 사용되지 않습니다.
다만 성능이 올라가는 경우가 더러 있기 때문에 캐글이나 데이콘과 같은 미세한 성능 차이로 승부를 결정하는 대회에서 주로 사용됩니다.
특히 기본 모델로 4개 이상을 선택해야 좋은 결과를 기대할 수 있다고 합니다!!
그럼 이제 스태킹의 원리에 대해 알아봅시다.
2. 스태킹의 원리
2-1. 목표
기본 모델들을 통해 예측된 값들을 학습용 데이터로 다시 이용한다?
예측값(y값)을 다시 학습데이터로 쓰면, 그 데이터의 target 변수(레이블)는 뭐야?
이런 궁금증을 정리시켜주기 위해 최종 모델의 모습을 보기 쉽게 시각화해봤습니다.
 최종 모델(메타 모델)의 데이터 모습
최종 모델(메타 모델)의 데이터 모습
여기서는 이것만 이해하시면 됩니다.
” 아~ 최종 모델에서는 y 예측값과 실제값이 독립변수와 종속변수로 작용하는구나. “
이제 저희가 알아야 할 것은 기본 모델들을 통해 ‘y_train_예측값’과 ‘y_test_예측값’ 데이터프레임을 만드는 것입니다.
결론부터 말씀드리면 해당 데이터 프레임은 기본 모델의 예측값들을 옆으로 쭉 붙인 것입니다.
마치 이렇게요!
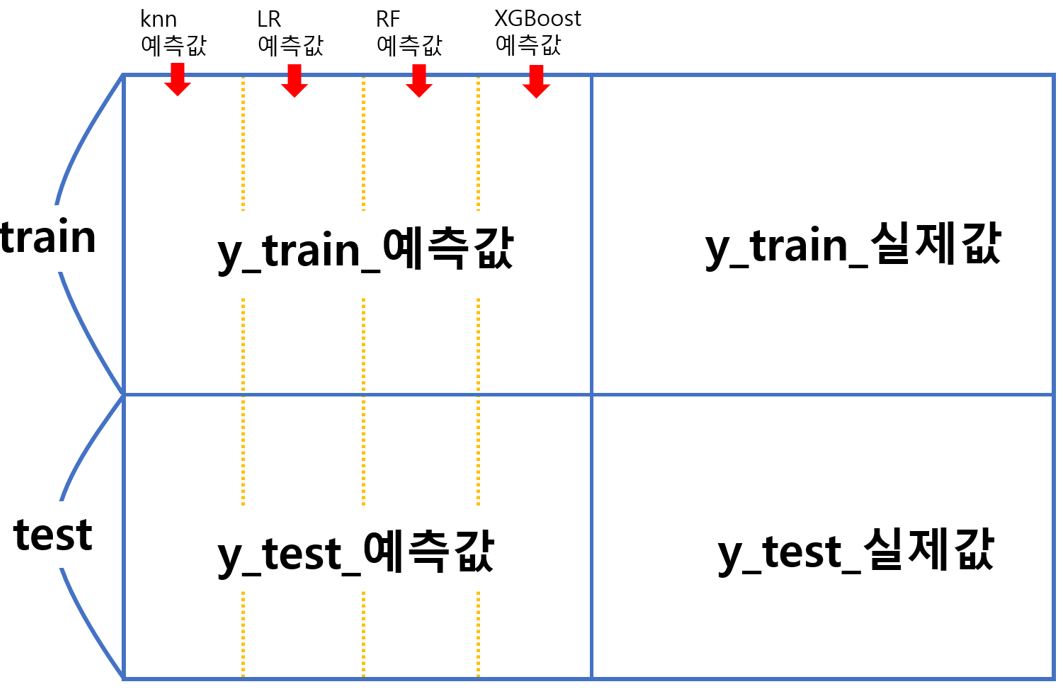
왜 하필 옆으로 붙인걸까요?
행 단위로 생각해보면 이해가 될 것입니다.
첫 행을 예로 들어보면, 각 모델들의 첫 번째 y_train 원소 값에 대한 예측값들이 있습니다.
즉 최종 모델이 하고자 하는 것은 y 실제값이 이정도 일 때, knn에서 이정도 값, 로지스틱 회귀에서 이정도 값, 랜덤 포레스트에서 이정도 값, XGBoost에서 이정도 값을 예측한다 는 것을 학습시키는 것입니다.
그렇다면 학습된 모델은 기본 모델들의 예측값을 통해 실제값을 예측할 수 있겠죠?
스태킹이 이런 원리로 작동되는 것입니다.
###
2-2. 기본모델
4종류의 기본 모델 중 한 가지 모델의 동작 원리를 살펴보겠습니다(나머지 모델도 동일한 원리를 가집니다).
먼저 과적합(overfitting) 방지를 위해 교차검증을 실시합니다(ex. 3회).
그럼 아래와 같은 그림처럼 X-train을 3등분으로 나누어서 표현할 수 있는데요,
 기본 모델을 교차검증한 모습
기본 모델을 교차검증한 모습
X_train 중 두 부분을 모델의 학습데이터로 사용하고, 나머지는 테스트 데이터로 사용합니다.
아래와 같이 말이죠!
여기서 핵심은 두 부분으로 학습시킨 모델로 두 번 테스트를 한다는 것입니다.
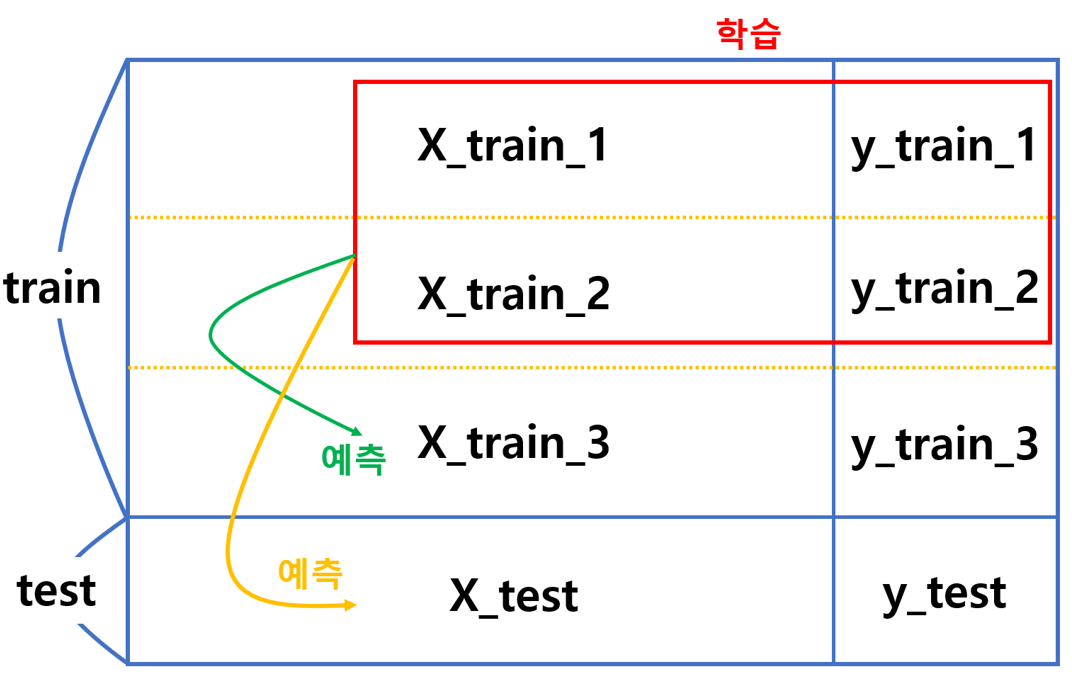
첫 번째 예측으로 y_train_3 에 대한 예측값(y_train_3_pred)이 생기고,
두 번째 예측으로 y_test 에 대한 예측값(y_test_pred_1)이 생깁니다.
그 다음, 학습 데이터로 X_train_1과 X_train_3를 사용하고, 테스트 데이터로 X_train_2와 X_test를 사용합니다.
그 결과로 y_train_2 에 대한 예측값(y_train_2_pred)이 생기고,
y_test 에 대한 예측값(y_test_pred_1)이 생깁니다.
마지막으로, 학습 데이터로 X_train_2과 X_train_3를 사용하고, 테스트 데이터로 X_train_1와 X_test를 사용합니다.
그 결과로 y_train_1 에 대한 예측값(y_train_1_pred)이 생기고,
y_test 에 대한 예측값(y_test_pred_1)이 생깁니다.
결국 y_train_1_pred 부터 y_train_3_pred 까지 총 3개를 쌓아 ‘y_train_예측값’을 구했습니다.
그리고 폴드마다 y_test를 예측한 값들을 평균내서 ‘y_test_예측값’을 구했습니다.
이해를 돕기위해 코드를 첨부합니다.
from sklearn.neighbors import KNeighborsClassifier
# 객체 생성
knn_clf = KNeighborsClassifier()
# 모델 학습
knn_clf.fit(X_train_1_2, y_train_1_2)
# 테스트
y_train_3_pred = knn_clf.predict(X_train_3) # y_train_3에 대한 예측
y_test_pred_1 = knn_clf.predict(X_test) # y_test에 대한 예측
#... X_train_2_3에 대한 예측, X_train_1_3에 대한 예측도 같은 방법으로 진행합니다.
# 결과
y_train_pred = pd.concat([y_train_1_pred, y_train_2_pred, y_train_3_pred], axis=0)
y_test_pred = np.mean(y_test_pred_1, y_test_pred_2, y_test_pred_3)
지금 구한 값이 전체에서 어떤 역할을 하느냐?
아래 그림의 빨간 상자인 한 열을 생성한 것입니다.
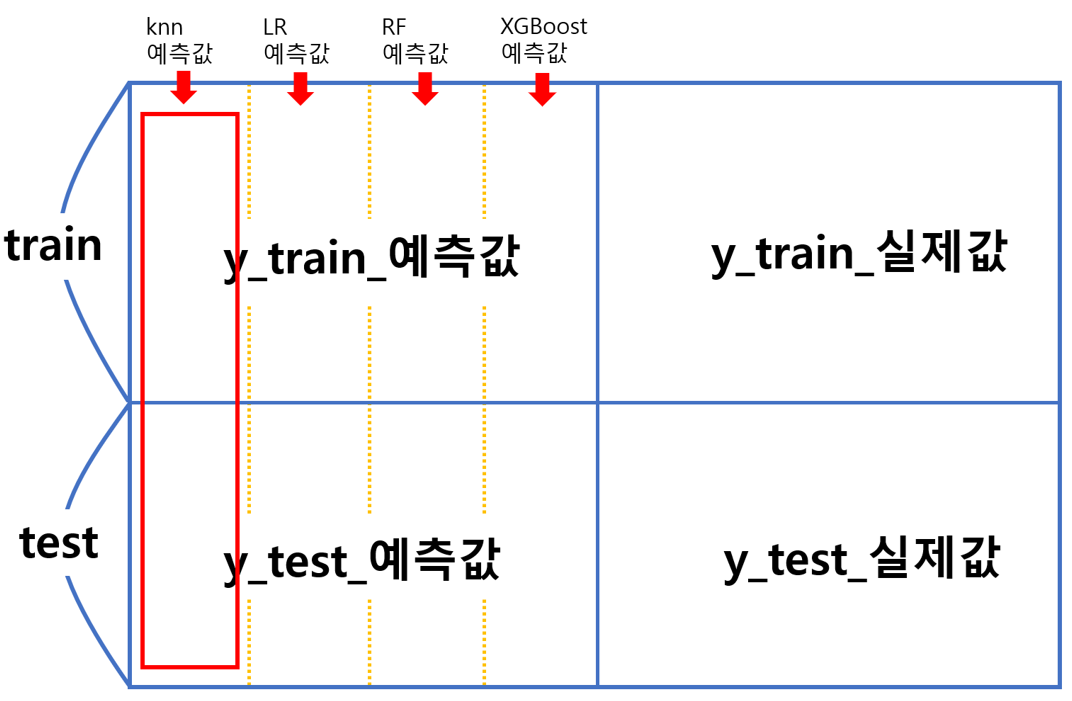
이제 다른 모델들도 같은 방식으로 y_train_예측값과 y_test_예측값을 구하고,
옆으로 쭉 이어 붙이면 최종 모델을 위한 학습데이터를 완성하는 것입니다.
2-3. 최종모델
다음은 최종 모델의 학습데이터 모습입니다.
이 학습데이터는 개별 모델의 교차검증으로부터 예측된 값들로 구성되어있고,
학습데이터의 레이블은 기존 데이터의 y_train 값입니다.
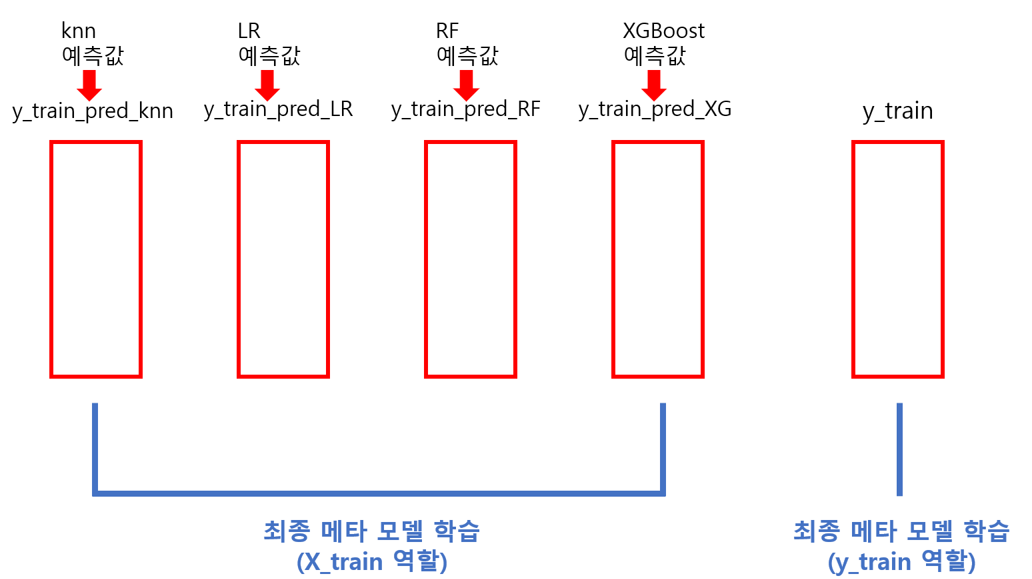 메타 모델의 학습 데이터
메타 모델의 학습 데이터
다음은 최종 모델의 테스트 데이터 입니다.
테스트 데이터 역시 개별 모델로부터 만들어졌고,
위 그림의 학습 데이터로 학습된 모델에 아래 그림의 테스트 데이터를 입력하면 우리가 원하는 타겟값인 y_test 값이 나옵니다.
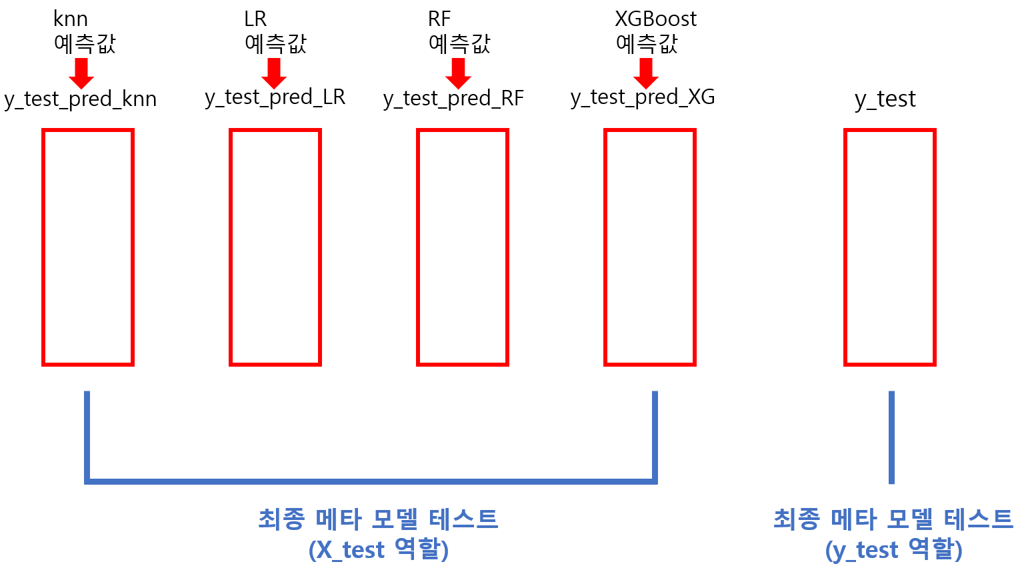 메타 모델의 테스트 데이터
메타 모델의 테스트 데이터
전체적인 구조를 위해 한번 정리해봤습니다!!
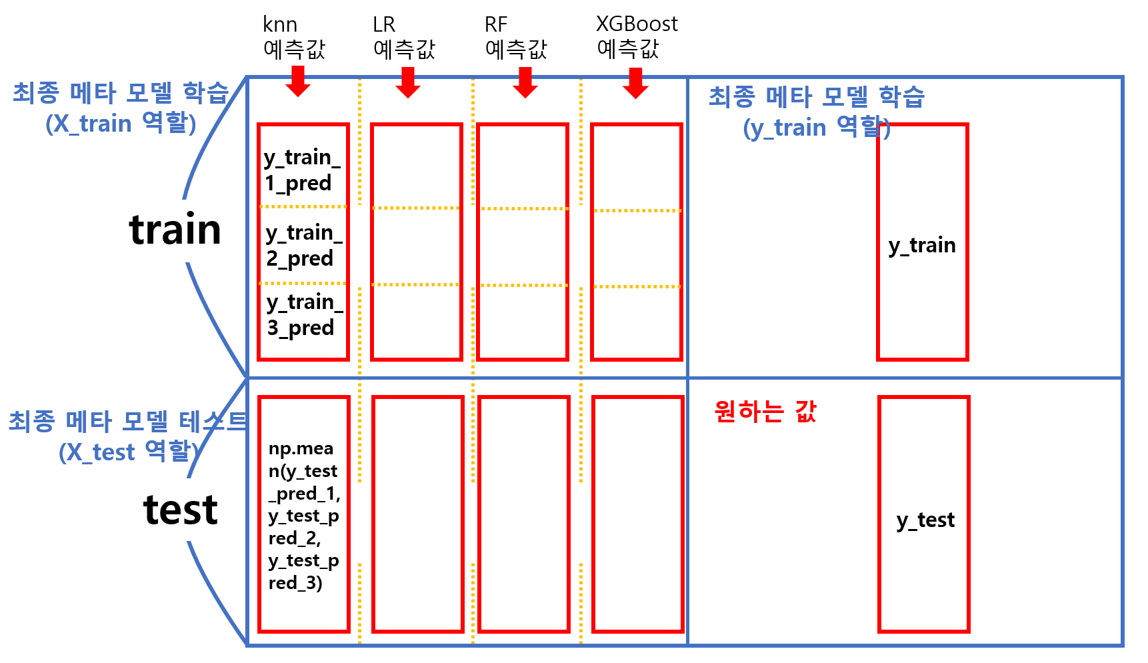 메타 모델 구조도
메타 모델 구조도
###
Source : https://hwi-doc.tistory.com/entry/%EC%8A%A4%ED%83%9C%ED%82%B9Stacking-%EC%99%84%EB%B2%BD-%EC%A0%95%EB%A6%AC