-
Support Vector Machine 이란?
- 분류(classification), 회귀(regression), 특이점 판별(outliers detection) 에 쓰이는
- 지도 학습 머신 러닝 방법 중 하나이다.
SVM 의 종류
- scikit-learn 에서는 다양한 SVM 을 지원한다.
- SVC
- Classification 에 사용되는 SVM 모델을 의미하며,
- SVM 의 끝문자인 M 을 Classification 의 첫 문자인 C 로 바꾼 것이다.
- SVR
- Regression 에 사용되는 SVM 모델을 의미하며,
- SVM 의 끝문자인 M 을 Regression 의 첫 문자인 R 로 바꾼 것이다.
- 특이점 판별(outlier detection) 에는 OneClassSVM 이 사용된다.
SVC (Support Vector Classification)
-
예시와 함께 보면 좀 더 쉽게 이해할 수 있다.

-
예를 들어, ㅇ과 ㅁ의 두 범주를 나누는 분류 문제를 푼다고 가정해보자.
-
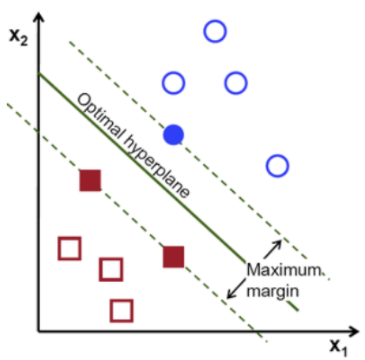
구분을 위해 두 범주 사이에 선을 긋는다고 한다면, 위 그림과 같이 다양한 방법으로 선을 그을 수 있다.
-
만약, 위 그림처럼 두 개의 점선으로 두 그룹을 구분할 수 있다면
-
두 점선 간 거리를 마진(Margin) 이라고 하며
-
마진이 최대값을 가질 때의 중간 경계선을, 최적 초평면(optimal hyperplane) 또는 결정 경계(Decision Boundary) 라고 한다.
-
따라서, SVM 은 각 그룹이 최대로 떨어질 수 있는 최대 거리(최대마진)를 찾고 ,
-
해당 거리의 중간지점(최적 초평면)으로 각 그룹을 구분짓는 기법이다.
-
-
이와 같은 SVC 는 데이터가 선형인 경우에는 잘 작동하지만, 데이터가 비선형인 경우에는 잘 작동하지 않을 수 있다.
SVR (Support Vector Regression)
- 이제, SVM 을 회귀에 적용시켜보자.
-
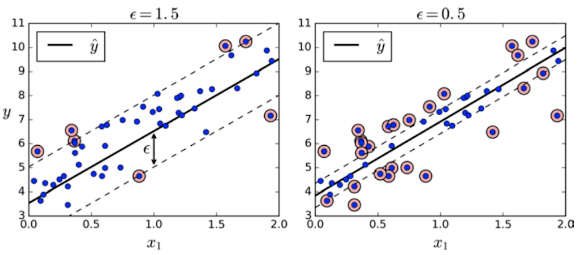
SVM 을 회귀에 적용하는 방법은, SVC 와 목표를 반대로 하는 것이다.
-
즉, 마진 내부에 데이터가 최대한 많이 들어가도록 학습하는 것이다.
-
마진의 폭은 epilson 이라는 하이퍼파라미터를 사용하여 조절한다.
-
간단한 SVR 예제 코드
import numpy as np from sklearn import datasets from sklearn.svm import SVR from sklearn.metrics import mean_squared_error, explained_variance_score from sklearn.utils import shuffle data = datasets.load_boston() X, y = shuffle(data.data, data.target, random_state = 7) num_training = int(0.8 * len(X)) X_train, y_train = X[:num_training], y[:num_training] X_test, y_test = X[num_training:], y[num_training:] # Create Support Vector Regression model # kernel : 선형 커널 # C : 학습 오류에 대한 패널티, C 값이 클 수록 모델이 학습 데이터에 좀 더 최적화 됨, 너무 크면 오버피팅 발생 # Epsilon : 임계값, 예측한 값이 GT 범위 안에 있으면 패널티 부여 X sv_regressor = SVR(kernel='linear', C=1.0, epsilon=0.1) sv_regressor.fit(X_train, y_train) y_pred = sv_regressor.predict(X_test) Source : https://wooono.tistory.com/111 mse = mean_squared_error(y_test, y_pred) evs = explained_variance_score(y_test, y_pred) test_data = [3.7, 0, 18.4, 1, 0.87, 5.95, 91, 2.5052, 26, 666, 20.2, 351.34, 15.27] print(sv_regressor.predict([test_data])[0])