-
-
의사 결정 트리 (Decision Tree)
-
먼저, 의사 결정 트리 (decision tree)의 개념부터 다뤄보겠습니다.
-
의사 결정 트리는, 특정 Feature 에 대한 질문을 기반으로 데이터를 분리하는 방법입니다.
- 사람들이 일상생활에서 어떠한 의사 결정을 내리는 과정과 매우 비슷합니다.
-
건강 위험도를 결정하는 의사 결정 트리로 예를 들어 보겠습니다.
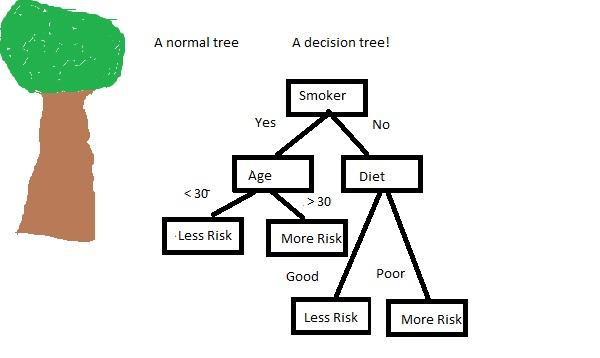
- 어떠한 사람에 대한 정보(feature)가 주어졌을 때,
- “흡연자인지, 몇살인지, 다이어트는 하고 있는지” 등의 질문을 통해, 해당 사람을 논리적으로 분리할 수 있게 됩니다.
랜덤 포레스트 (Random Forest)
- 이제 Random Forest 에 대해서 다뤄보겠습니다.
- Forest(숲)은 무엇으로 이루어져 있을까요? 나무입니다.
- 수많은 나무가 한군데 어우러져 비로소 울창한 숲을 만드는 것이죠.
- 마찬가지로 Random Forest는, 수많은 의사 결정 트리(Decision Tree)가 모여서 생성됩니다.
- 상단 의사 결정 트리 예제에서는, 건강 위험도를 세 가지 요소와 한가지 의사 결정 트리로 인해서 결정했습니다.
- 하지만, 건강 위험도를 예측하려면 세 가지 요소보다 더 많은 요소를 고려하는 것이 바람직할 것입니다.
- 예를 들어, 성별, 키, 몸무게, 거주지역, 운동량, 기초 대사량, 근육량 등 수많은 요소도 건강에 큰 영향을 미칩니다.
- 하지만, 이렇게 수많은 요소(Feature)들을 기반으로 건강 위험도(Target)를 예측한다면, 분명 오버피팅이 일어날 것입니다.
- 예를 들어, Feature가 30개라고 합시다.
- 30개의 Feature를 기반으로 하나의 결정 트리를 만든다면 트리의 가지가 많아질 것이고, 이는 오버피팅이 될 것입니다.
- 따라서, Random Forest 는 전체 Feature 중 랜덤으로 일부 Feature만 선택해 하나의 결정 트리를 만들고, 또 전체 Feature 중 랜덤으로 일부 Feature를 선택해 또 다른 결정 트리를 만들며, 여러 개의 의사 결정 트리를 만드는 방식으로 구성됩니다.
- 의사 결정 트리마다 하나의 예측 값을 내놓습니다.
- 이렇게 여러 결정 트리들이 내린 예측 값들 중, 가장 많이 나온 값을 최종 예측값으로 정합니다.
- 다수결의 원칙에 따르는 것입니다.
- 이렇게 여러 가지 결과를 합치는 방식을 앙상블(Ensemble)이라고 합니다.
- 즉, 하나의 거대한 (깊이가 깊은) 결정 트리를 만드는 것이 아니라 여러 개의 작은 결정 트리를 만드는 것입니다.
- 여러 개의 작은 결정 트리가 예측한 값들 중, 가장 많이 등장한 값(분류일 경우) 혹은 평균값(회귀일 경우)을 최종 예측 값으로 정하는 것입니다.
- 문제를 풀 때도 한 명의 똑똑한 사람보다 100 명의 평범한 사람이 더 잘 푸는 원리입니다.
- 그럼 다시, Random Forest의 Random은 무엇이 무작위적이라는 것일까요?
- Random은, 각각의 의사 결정 트리를 만드는데 있어 쓰이는 특징들을(흡연 여부, 나이, 등등) 무작위로 선정한다는 의미입니다.
- 예를 들어, 건강 위험도를 30개의 특징들로 설명할 수 있다면,
- 30개의 특징들 중 무작위로 일부만 선택하여,
- 가장 건강 위험도를 잘 예측할 수 있는 하나의 트리를 구성한다는 의미입니다.
- 다음은 Random Forest가 완성되는 과정입니다.
- 전체 특징 중 일부 특징을 무작위로 선택합니다.
- 흡연 여부, 키, 몸무게, 나이가 선택되었다고 가정합니다.
- 선택된 일부 특징을 사용해, 가장 건강 위험도를 잘 예측할 수 있는 하나의 트리를 구성합니다.
- 원하는 개수의 트리가 생성되기까지 위 과정을 반복합니다.
- 트리의 개수는 데이터 사이언티스트가 원하는 만큼 생성이 가능합니다.
- 전체 특징 중 일부 특징을 무작위로 선택합니다.
- 그렇다면, 왜 Random Forest는 의사 결정 트리의 한 단계를 만들 때마다 모든 요소를 고려하지 않을까요?
- 그것은 역설적으로 모든 요소를 고려하기 위함입니다.
- 만약 의사 결정 트리의 한 단계를 만드는데 모든 요소를 고려한다면,
- 모든 의사 결정 트리가 같은 5~6개의 요소만을 가지고 생성되겠죠.
- 고려해야 할 요소는 30개인데, 모든 트리가 흡연 여부, 나이, 식단, 몸무게, 성별 등으로 구성되게 됩니다.
- 하지만, 아무리 5~6개의 요소가 가장 “똑똑한” 요소들 이어도, 나머지 25개의 “덜 똑똑한” 요소들을 고려하는 것이 최종 목적입니다.
- 전교 1등 한 명보다 전교 5등 100명이 아는 것이 더 많은 것과 비슷한 원리입니다.
- 이처럼 여러 개의 결정 트리를 통해 랜덤 포레스트를 만들면 오버피팅 되는 단점을 해결할 수 있습니다.
랜덤 포레스트의 장점
- Classification(분류) 및 Regression(회귀) 문제에 모두 사용 가능
- Missing value(결측치)를 다루기 쉬움
- 대용량 데이터 처리에 효과적
- 모델의 노이즈를 심화시키는 Overfitting(오버피팅) 문제를 회피하여, 모델 정확도를 향상시킴
- Classification 모델에서 상대적으로 중요한 변수를 선정 및 Ranking 가능
Scikit-learn 예제 코드 및 파라미터
-
n_estimators: 랜덤 포레스트 안의 결정 트리 갯수
- n_estimators는 클수록 좋습니다.
- 결정 트리가 많을수록 더 깔끔한 Decision Boundary가 나오겠죠.
- 하지만 그만큼 메모리와 훈련 시간이 증가합니다.
- Default는 10입니다.
-
max_features: 무작위로 선택할 Feature의 개수
- max_features=n_features이면 30개의 feature 중 30개의 feature 모두를 선택해 결정 트리를 만듭니다.
- 단, bootstrap=True이면 30개의 feature에서 복원 추출로 30개를 뽑습니다.
- 특성 선택의 무작위성이 없어질 뿐 샘플링의 무작위성은 그대로인 것입니다.
- bootstrap=True는 default 값입니다.
- 따라서 max_features 값이 크다면 랜덤 포레스트의 트리들이 매우 비슷해지고, 가장 두드러진 특성에 맞게 예측을 할 것입니다.
- max_features 값이 작다면 랜덤 포레스트의 트리들이 서로 매우 달라질 것입니다. 따라서 오버피팅이 줄어들 것입니다.
- max_features는 일반적으로 Defalut 값을 씁니다.
-
max_depth : 트리의 깊이를 뜻합니다.
-
min_samples_leaf : 리프노드가 되기 위한 최소한의 샘플 데이터 수 입니다.
-
min_samples_split : 노드를 분할하기 위한 최소한의 데이터 수 입니다.
-
max_leaf_nodes : 리프노드의 최대 개수
-
분류 코드 (RandomForestClassifier)
from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score classifier = RandomForestClassifier(n_estimators = 100) classifier.fit(X_train, y_train) y_pred = classifier.predict(X_test) print("정확도 : {}".format(accuracy_score(y_test, y_pred)) -
회귀 코드 (RandomForestRegressor)
from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error regressor = RandomForestRegressor() regressor.fit(X_train, y_train) y_pred = regressor.predict(X_test) mse = np.sqrt(mean_squared_error(y_pred, y_test)) print('평균제곱근오차 : ', mse) -
GridSearchCV를 통한 랜덤포레스트분류의 하이퍼 파라미터 튜닝
from sklearn.model_selection import GridSearchCV grid = { 'n_estimators' : [100,200], 'max_depth' : [6,8,10,12], 'min_samples_leaf' : [3,5,7,10], 'min_samples_split' : [2,3,5,10] } classifier_grid = GridSearchCV(classifier, param_grid = grid, scoring="accuracy", n_jobs=-1, verbose =1) classifier_grid.fit(X_train, y_train) print("최고 평균 정확도 : {}".format(classifier_grid.best_score_)) print("최고의 파라미터 :", classifier_grid.best_params_) -
파라미터 중요도 시각화
import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline feature_importances = model.feature_importances_ ft_importances = pd.Series(feature_importances, index = X_train.columns) ft_importances = ft_importances.sort_values(ascending=False) plt.figure(fig.size(12,10)) sns.barplot(x=ft_importances, y= X_train.columns) plt.show()Source : https://wooono.tistory.com/115
-
-