Ml_1
*1. 로지스틱 회귀(Logistic Regression)*
로지스틱 회귀(Logistic Regression)는 분류 문제를 위한 회귀 알고리즘으로, *0에서 1사이의 값*만 내보낼 수 있도록 출력값의 범위를 수정한 분류 알고리즘입니다.
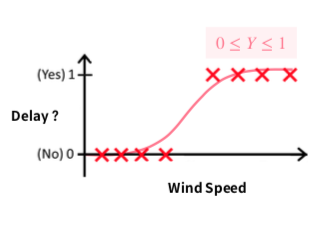
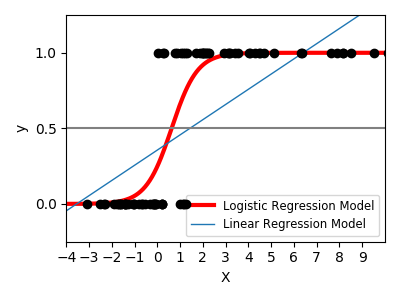
이번 시간에는 사이킷런 안에 구현되어 있는 로지스틱 회귀 호출을 통해 실제로 S자형 곡선 그래프가 출력되는지 시각화를 통해 확인해 보겠습니다.
*로지스틱 회귀를 위한 사이킷런 함수/라이브러리*
-
from sklearn.linear_model import LogisticRegression: 사이킷런 안에 구현되어 있는 로지스틱 회귀 기능을 불러옵니다. -
model=LogisticRegression(): 로지스틱 회귀 모델logistic_model을 정의합니다. -
model.fit(X, y): (X, y) 데이터셋에 대해서logistic_model모델을 학습시킵니다. -
model.predict(X): X 데이터에 대해logistic_model이 예측한 값을 반환합니다.*실습*
- 로지스틱 회귀 모델을 구현하고, 학습 결과를 확인할 수 있는
main()함수를 완성합니다. -
- 함수를 이용하여 데이터를 불러옵니다.
- 로지스틱 회귀 모델을 정의합니다.
- 학습용 데이터로 로지스틱 회귀 모델을 학습시킵니다.
- 테스트용 데이터로 예측한 분류 결과를 확인합니다.
- 실행 버튼을 눌러 실제 학습된 로지스틱 회귀 모델이 S자 곡선을 그리는지 확인합니다.
[실행 결과]
- 로지스틱 회귀 모델을 구현하고, 학습 결과를 확인할 수 있는
## Tips!
-
지시사항에 따라 None값을 채웁니다.
-
None값이 아닌 주어진 값을 변경하면 오류가 발생할 수 있습니다.
*2. SVM(Support Vector Machine)*
서포트 벡터 머신은 높은 성능을 보여주는 대표적인 분류 알고리즘입니다.
특히 이진 분류를 위해 주로 사용되는 알고리즘으로, 각 클래스의 가장 외곽의 데이터들 즉, *서포트 벡터*들이 가장 멀리 떨어지도록 합니다.
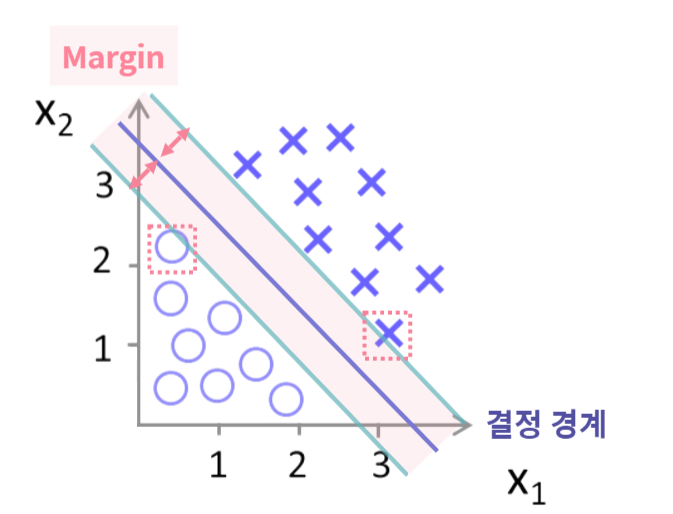
이번 실습에서는 0과 1로 분류되어 있는 데이터 셋에서, SVM을 사용하여 데이터가 올바르게 분류되는지 확인해보겠습니다.
*SVM을 위한 사이킷런 함수/라이브러리*
from sklearn.svm import SVC: SVM 모델을 불러옵니다.model=SVC(): SVM 분류 모델svm을 정의합니다.model.fit(X, y): (X, y) 데이터셋에 대해서svm모델을 학습시킵니다.model.predict(X): X 데이터에 대해svm이 예측한 값을 반환합니다.
*실습*
- data 폴더 내에 있는 ‘dataset.csv’파일을 불러오고, 학습용 데이터와 테스트용 데이터를 분리하여 반환하는
load_data()함수를 구현합니다. -
- pandas의
read_csv()함수를 이용하여 data 폴더 내에 있는dataset.csv파일을 불러옵니다. - 데이터
X와y를 분리합니다. 데이터 폴더에 있는dataset.csv파일을 확인합니다. X데이터에는'Class'컬럼을 제외한 나머지 컬럼들을,y데이터에는'Class'컬럼을 분리하여 저장합니다.
- pandas의
- SVM 모델을 불러오고, 학습용 데이터에 맞추어 학습 시킨 후, 테스트 데이터에 대한 예측값을 반환하는 함수
SVM()을 완성합니다. -
- SVM 모델을 정의합니다.
- SVM 모델을 학습용 데이터에 맞추어 학습시킵니다.
- 학습된 모델을 이용하여 테스트 데이터에 대한 예측을 수행합니다.
- 실행 버튼을 눌러 분류 결과를 확인합니다.
-
- 결과로 출력되는 매트릭스는 Confusion Matrix와 분류 성능을 나타내는 지표입니다. 추후에 학습할 내용이지만 미리 눈으로 익혀보세요.
Tips!
- pandas의 DataFrame에 쓸 수 있는
drop메소드를 활용하면 DataFrame에서 원하는 column(열)의 이름을 통해 해당 column을 삭제할 수 있습니다.
data = pd.read_csv('dataset.csv') X = data.drop('Class', axis=1)Copy-
지시사항에 따라 None값을 채웁니다.
-
None값이 아닌 주어진 값을 변경하면 오류가 발생할 수 있습니다.
*3. 선형 SVM 모델 - 학습 및 평가, 예측*
이번 실습에선 scikit-learn을 사용해서 SVM 모델을 생성하고, 전처리한 데이터를 활용해 모델의 학습 및 평가, 예측 과정까지 살펴보겠습니다.
또한 학습 이후에 SVM 모델이 생성한 분류 경계면과 그에 해당하는 서포트 벡터까지 확인해보겠습니다.
### *코드 구성*
preprocess.py: data 폴더 안의 iris.csv 파일을 읽고 데이터를 저장합니다.svm.py: scikit-learn을 사용해 SVM 모델을 생성하고, 주어진 데이터에 대해 모델을 학습시킵니다. 이후 검증용 데이터를 가지고 모델의 성능을 평가합니다.main.py: 작성한 코드를 활용하여 데이터를 읽고 저장하며, 모델을 학습시키고 평가하는 함수를 실행합니다.graph_plot.py: 저장된 데이터를 그래프로 출력합니다.## 실습
##### 1.
svm.py-
train_model()함수를 완성합니다. 아래의 코드 설명을 참고하여 SVM 모델을 불러오고 학습시킵니다.-
from sklearn import svm: scikit-learn에서 SVM 모델을 불러옵니다. -
svm.SVC(kernel, C): SVM 모델을 생성합니다.
kernel: SVM 모델의 커널 함수를 설정합니다. 이번 실습에선 선형(linear) 커널 함수를 사용합니다.C: SVM 모델의 슬랙변수 가중치 C를 설정합니다. 이번 실습에선 값을 80으로 사용합니다.
[Model].fit(X,y): 생성한 모델에 데이터 X와 y를 학습시킵니다.
-
-
evaluate_model()함수를 완성합니다. 검증용으로 주어진 데이터를 이용해서 모델 성능을 정확도로 측정합니다. 아래의 코드를 참고하세요.[Model].score(X, y): 검증용 데이터 X와 y를 이용해서 측정한 모델의 정확도를 반환합니다.
##### 2.
main.py- svm.py 안의 함수를 사용해 SVM 모델을 불러오고 학습시킵니다.
- svm.py 안의 함수를 사용해, 학습된 모델의 성능을 정확도로써 측정합니다.
## 4. 커널의 종류에 따라 변화하는 SVM 모델
이번 실습에선 커널의 종류에 따라 변화하는 SVM 분류기의 학습 과정 및 성능, 시각화 결과를 살펴보겠습니다. 활용할 데이터는 [실습1]에서 전처리한 데이터입니다.
슬랙 변수 가중치 𝐶C는 특정 값으로 고정 후, 이론 자료에서 학습했던 선형, 다항, RBF, 시그모이드 커널을 직접 적용해보고 시각화하여 그 성능을 비교하겠습니다.
### 코드 구성
preprocess.py : data 폴더 안의 iris.csv 파일을 읽고 데이터를 저장합니다.
svm.py : scikit-learn을 사용해 네 개의 SVM 모델을 생성하고, 주어진 데이터에 대해 네 모델을 학습시킵니다. 이후 검증용 데이터를 가지고 네 모델의 성능을 평가합니다.
main.py : 작성한 코드를 활용하여 데이터를 읽고 저장하며, 모델을 학습시키고 평가하는 함수를 실행합니다.
graph_plot.py : 저장된 데이터를 그래프로 출력합니다.
## 실습
##### 1. svm.py
-
train_linear_model()함수를 완성합니다. 아래의 코드 설명을 참고하여 SVM 모델을 불러오고 학습시킵니다.-
from sklearn import svm: scikit-learn에서 SVM 모델을 불러옵니다. -
svm.SVC(kernel, C): SVM 모델을 생성합니다.
kernel: SVM 모델의 커널 함수를 선형(linear) 로 설정합니다.C: SVM 모델의 슬랙변수 가중치 C를 10으로 설정합니다.
[Model].fit(X,y): 생성한 모델에 데이터 X와 y를 학습시킵니다.
-
-
train_poly_model()함수를 완성합니다. 마찬가지로 SVM 모델을 불러오고 학습시킵니다. 이때 커널 함수는 다항(poly), 슬랙변수 가중치 𝐶C는 10으로 설정합니다. -
train_rbf_model()함수를 완성합니다. 마찬가지로 SVM 모델을 불러오고 학습시킵니다. 이때 커널 함수는 RBF(rbf), 슬랙변수 가중치 𝐶C는 10으로 설정합니다. -
train_sig_model()함수를 완성합니다. 마찬가지로 SVM 모델을 불러오고 학습시킵니다. 이때 커널 함수는 시그모이드(sigmoid), 슬랙변수 가중치 𝐶C는 10으로 설정합니다. -
evaluate_model()함수를 완성합니다. 검증용으로 주어진 데이터를 이용해서 모델 성능을 정확도로 측정합니다. 아래의 코드를 참고하세요.[Model].score(X, y): 검증용 데이터 X와 y를 이용해서 측정한 모델의 정확도를 반환합니다.
##### 2. main.py
-
svm.py 안의 함수를 사용해 네 SVM 모델을 불러오고 학습시킵니다.
-
svm.py 안의 함수를 사용해, 학습된 두 모델의 성능을 정확도로써 측정합니다.
-
*5. 베이즈 정리로 나이브 베이즈 분류 구현하기*
나이브 베이즈 분류는 데이터의 확률적 속성을 가지고 클래스를 판단하는, 꽤 높은 성능을 가지는 머신러닝 알고리즘입니다.
이를 이해하기 위해서 Bayes’ Theorem에 친숙해질 필요가 있습니다.
간단한 나이브 베이즈 분류 구현을 통해 베이즈 정리에 대해 이해해 보도록 하겠습니다.
Bayes’ theorem : P(Y∣X)=P(X)P(X∣Y)∗P(Y)
데이터셋 내에서 *X와 Y의 빈도수를 활용*하여 연산에 필요한 각각의 확률값을 계산할 수 있습니다.
엘리스의 이메일을 한 번 들여다보면서 Bayes’ theorem을 이해해 볼까요? 엘리스의 이메일은 다음과 같은 텍스트 목록을 가지고 있습니다.
타입 텍스트 *Spam* “(광고) XXX 지금 *확인* 해보세요.” 첨부파일 : exe Ham “[긴급]엘리스님, *확인* 부탁드립니다.” 첨부파일 : exe Ham “Git 오프라인 수업을 3일 간 합니다” *Spam* “제목없음” 첨부파일 : exe *Spam* “놓칠 수 없는 기회, *확인* 해보세요.”
엘리스의 메일함에는 *총 20개*의 메일이 들어있습니다. 그중 *스팸 메일은 8개*, *정상 메일은 12개*로 분류되어 있습니다. *“확인” 키워드를 가지는 메일이 7개*, *“확인”을 제외한 메일이 13개*라고 할 때, 다음과 같은 분포를 가집니다.
스팸 메일 정상 메일 개수 “확인” 5 2 7 나머지 3 10 13 개수 8 12 20 스팸 메일과 정상 메일에서 공통적으로 나타나는 키워드인 “*확인*“이 등장했을 때, 이 메일이 스팸 메일 인지, 정상 메일이 되는지에 대해 판별해 보도록 하겠습니다.
>>> P( “스팸 메일” “확인” ) = ? >>> P( “정상 메일” “확인” ) = ? *실습*
- “확인” 이라는 키워드가 등장했을 때 해당 메일이 스팸 메일인지 정상 메일인지 판별하기 위한 함수를 구현합니다.
bayes_theorem()함수를 완성합니다. -
p_spam: P(“스팸 메일”)-
p_confirm_spam: P(“확인”“스팸 메일”) p_ham: P(“정상 메일”)-
p_confirm_ham: P(“확인”“정상 메일” ) -
p_spam_confirm: P( “스팸 메일”“확인” ) -
p_ham_confirm: P( “정상 메일”“확인” )
- 실행 버튼을 눌러 확인 키워드가 들어있는 메일이 정상 메일일 확률과 스팸 메일일 확률을 확인합니다.
Tips!
- 지시사항에 따라 None값을 채웁니다.
- None값이 아닌 주어진 값을 변경하면 오류가 발생할 수 있습니다.
*6. 사이킷런을 활용한 나이브 베이즈 분류*
이전 실습에서는 메일 내에서 스팸 및 정상 메일을 분류할 때,
- X = ‘확인’ 키워드 유무(O or X)
- Y = 메일 결과 (스팸 or 정상)
로, *입력값* X*의 개수가 1개*였습니다.
하지만, 만약 이메일에서 ‘확인’ 키워드 말고도 ‘.exe 첨부파일’을 보냈는지, 안 보냈는지 혹은 메일 제목에 대괄호가 쓰였는지/안 쓰였는지 등의 다양한 입력값이 추가되어 스팸 메일을 분류한다면, 문제가 좀 더 복잡해질 것 같습니다.
이러한 복잡한 문제 해결을 위하여 사이킷런에는 나이브 베이즈 분류 모델을 구현하여, 모듈 호출을 통해 간단히 나이브 베이즈 분류를 사용할 수 있도록 하였습니다.
이번 실습에서는 Wine 데이터를 활용하여 나이브 베이즈 분류 방법 중 하나인 *가우시안 나이브 베이즈 모델*을 학습시키고 분류가 잘 되었는지 확인해 보겠습니다. *‘가우시안’은 ‘데이터들의 분포가 평균값을 중심으로 대칭적인’*이라는 뜻입니다.
특히 가우시안 나이브 베이즈 모델은 ‘확인’키워드 유무(O or X)와 같은 이산적 데이터가 아닌 연속적인 값 (예를 들어 3.14…)을 가진 데이터에 적용할 수 있다는 특징을 가지고 있습니다.
*가우시안 나이브 베이즈를 위한 사이킷런 함수/라이브러리*
sklearn.naive_bayes.GaussianNB: 가우시안 나이브 베이즈 모델을 불러 옵니다.model=GaussianNB(): 가우시안 나이브 베이즈 모델model을 정의합니다.model.fit(X, y): (X, y) 데이터셋에 대해서model모델을 학습시킵니다.model.predict(X): X 데이터에 대해model이 예측한 값을 반환합니다.
*실습*
- 사이킷런에 저장되어 있는 데이터를 불러오고, 불러온 데이터를 학습용, 테스트용 데이터로 분리하여 반환하는 함수
load_data()를 구현합니다. -
- 사이킷런에 저장되어 있는 데이터를
(X, y)형태로 불러옵니다. - 불러온 데이터를 학습용 데이터와 테스트용 데이터로 분리합니다. *학습용 데이터 : 80%, 테스트용 데이터 : 20%*
- 일관된 결과 확인을 위해
random_state를 *0*으로 설정합니다.
- 사이킷런에 저장되어 있는 데이터를
- 가우시안 나이브 베이즈 모델을 불러오고,학습을 진행한 후 테스트 데이터에 대한 예측값을 반환하는 함수
Gaussian_NB()를 구현합니다. -
- 가우시안 나이브 베이즈 모델을 정의합니다.
- 학습용 데이터에 대해 모델을 학습시킵니다.
- 테스트 데이터에 대한 모델 예측을 수행합니다.
- 실행 버튼을 눌러 분류 정확도를 확인해봅니다.
-
- 정확도에 대한 개념을 아직 학습하지 않았지만, 해당 지표는 높을수록 더 좋은 예측을 수행하는 모델이라고 할 수 있습니다.
- “확인” 이라는 키워드가 등장했을 때 해당 메일이 스팸 메일인지 정상 메일인지 판별하기 위한 함수를 구현합니다.
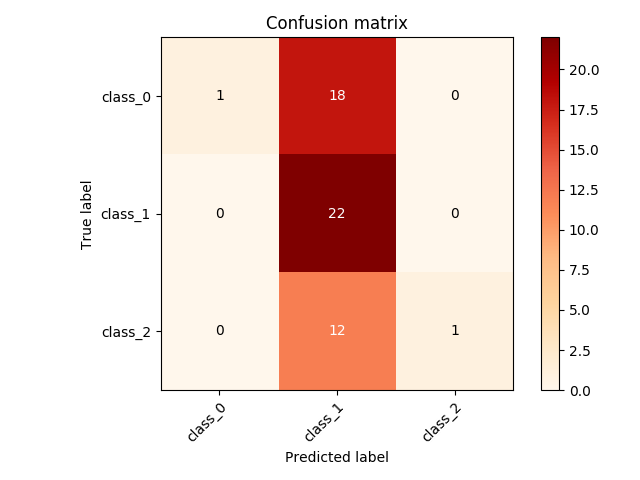
*7. 혼동 행렬(Confusion matrix)*
혼동 행렬(Confusion matrix)은 분류 문제에서 모델을 학습시킨 뒤, 모델에서 데이터의 X값을 집어넣어 얻은 *예상되는 y값*과, *실제 데이터의 y값*을 비교하여 정확히 분류되었는지 확인하는 메트릭(metric)이라고 할 수 있습니다.

위 표가 바로 혼동 행렬이며, 각 표에 속한 값은 다음을 의미합니다.
- True Positive (TP) : 실제 값은 Positive, 예측된 값도 Positive.
- False Positive (FP) : 실제 값은 Negative, 예측된 값은 Positive.
- False Negative (FN) : 실제 값은 Positive, 예측된 값은 Negative.
- True Negative (TN) : 실제 값은 Negative, 예측된 값도 Negative.
사이킷런 안에는 위 4개 평갓값을 얻기 위해 사용할 수 있는 기능이 정의되어 있습니다.
이번 실습에서는 3개의 클래스를 가진 다중 분류 데이터를 이용하여 혼동 행렬을 직접 출력해보고, 확인해보도록 하겠습니다.
*혼동 행렬을 위한 사이킷런 함수/라이브러리*
from sklearn.metrics import confusion_matrix: 혼동 행렬(Confusion matrix)을 위한 기능을 불러옵니다.-
confusion_matrix(y_true, y_pred)- Confusion matrix의 값을
np.ndarray로 반환해줍니다.
*실습*
- 데이터를 불러오는
load_data()함수와 혼동행렬 시각화를 위한plot_confusion_matrix()함수를 살펴봅니다. -
- 데이터를 불러 오고 분류 예측 결과를 평가하기 위한 혼동 행렬을 계산합니다.
- confusion matrix를 시각화하여 출력합니다.
plot_confusion_matrix함수의 인자를 참고하여 None을 채워보세요. test_y와y_pred를 비교합니다.- 함수의 인자
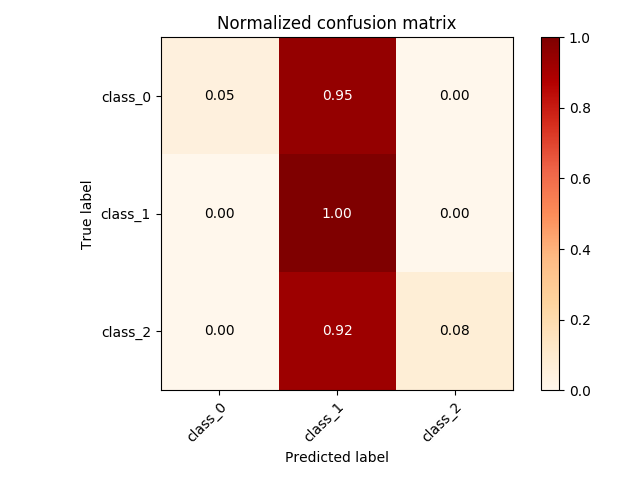
normalize값을True로 설정하여 정규화된 혼동 행렬 시각화 결과를 확인합니다.
- 정의되어 있는 함수를 이용하여 순서대로
main()함수를 완성합니다. - 실행 버튼을 눌러 이진 분류 뿐만 아니라 다중 클래스 데이터에서는 어떤 결괏값이 나오는지 확인합니다.
[실행 결과]