2. GBM (Gradient Boosting Machine)
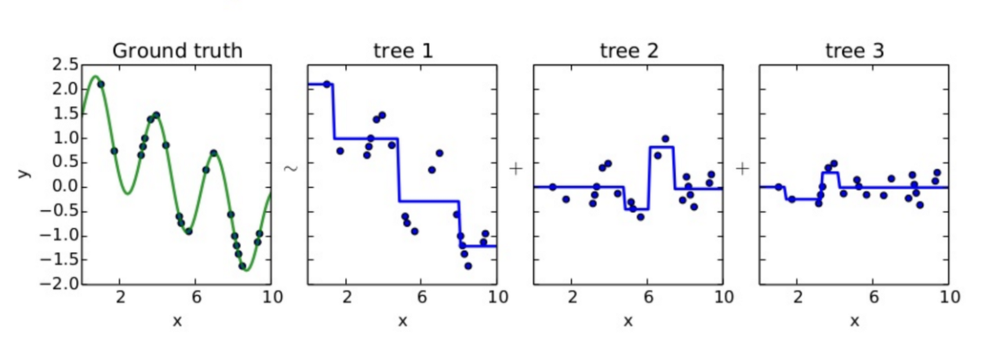
위 그림의 상황을 가정해보면, tree 1이 예측하고 남은 잔차들을 tree 2, tree 3를 차례로 지나가면서 줄여가는 것 부스팅 알고리즘이다. 각 tree들을 weak learner라고 보면 된다. 위에서 부스팅 알고리즘은 ‘가중치 부여를 통해’ 오류를 개선해 나간다고 했는데, GBM은 가중치 업데이트에 경사하강법을 이용하는 것이 큰 특징이다. 즉, 손실함수를 최소화하는 방향성을 가지고 가중치 값을 업데이트하는 것이라 할 수 있겠다. 경사하강법에 대해 정리한 포스트를 참고하면 좋겠다!
3. LightGBM
LightGBM은 XGBoost와 함께 부스팅 계열 알고리즘에서 가장 각광받고 있다. LightGBM의 가장 큰 장점은 학습에 걸리는 시간이 적다는 점이다(지금 참고하고 있는 책에서는 GBM->XGBoost->LightGBM 순으로 빠르다고 한다). 그리고 XGBoost와의 예측 성능 차이가 크게 나지도 않는다. 반면 적은 데이터셋에 적용시 과적합이 발생하기 쉽다는 것이 단점이다. 여기서 ‘적은 데이터셋’이라 함은 통상적으로 10,000건 이하의 데이터셋 정도라고 LightGBM 공식 도큐먼트에서 기술하고 있다.
필자가 생각하는 LightGBM의 특장점은 카테고리형 피처의 자동 변환이 가능하고 최적 분할이 된다는 것이다. 이게 무슨 말이냐 하면, 원-핫 인코딩과 같은 범주형 변수->수치형 변수로 바꿔주는 과정을 사용하지 않고도 범주형 변수를 최적으로 변환하고 이에 따른 노드 분할 수행이 이루어진다는 것이다! Tabular 데이터를 다뤄본 사람은 알 것이다. 기본적으로 머신러닝 알고리즘은 문자열 값을 입력 값으로 허용하지 않는다. 그래서 문자열 피처를 피처 벡터화(feature vectorization) 등의 기법으로 벡터화하는 것이다. 하지만 가끔 범주형 피처가 너무 많으면, 혹은 피처 안에 속성의 종류가 너무 많으면 어떻게 인코딩을 해야하는지 막막하게 느껴질 때가 있다. 이때 LightGBM이 유용하게 쓰일 수 있다. 이를 위해 tuning 해줘야 할 파라미터는 뒤에 설명하겠다.
이외에 또다른 장점으로는 메모리 사용량이 작다는 것도 들 수 있다.
기본 구조
일반 GBM 계열 트리 분할 방법과 다르게 리프 중심 트리 분할(leaf wise) 방식을 사용한다. 대부분의 기존 트리 기반 알고리즘은 균형 트리 분할(level wise) 방식을 사용한다.
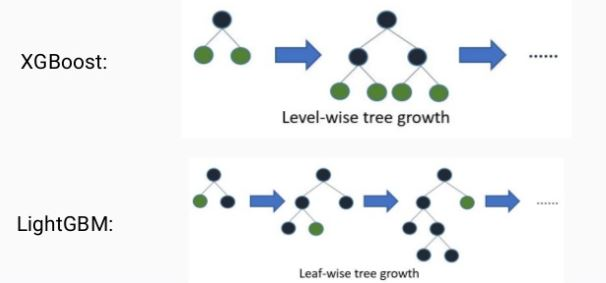 XGBoost는 전형적인 level-wise 방식이고, LightGBM은 leaf-wise 트리 분할 방식을 따른다.
XGBoost는 전형적인 level-wise 방식이고, LightGBM은 leaf-wise 트리 분할 방식을 따른다.
- level-wise 트리 분할: 균형 잡힌 트리 모양을 유지함으로써 트리의 깊이를 효과적으로 줄임 -> overfitting에 강함(대신 트리 균형을 맞추는 데에 시간이 소요됨)
- leaf-wise 트리 분할: 트리의 균형을 맞추지 않고, 최대 손실값(max delta loss)을 가지는 리프 노드 분할 -> 예측 오류 손실을 최소화 할 수 있음(대신 트리의 깊이가 깊어지고 비대칭적임)
하이퍼 파라미터
초기에는 파이썬 래퍼용 LightGBM 패키지만 제공되었으나 지금은 scikit-learn과의 호환성을 지원하기 위해 scikit-learn 래퍼 LightGBM이 추가로 개발되었다. 공식 도큐먼트에서 가져온 것들 중에 중요한 것들만 살펴보겠다.
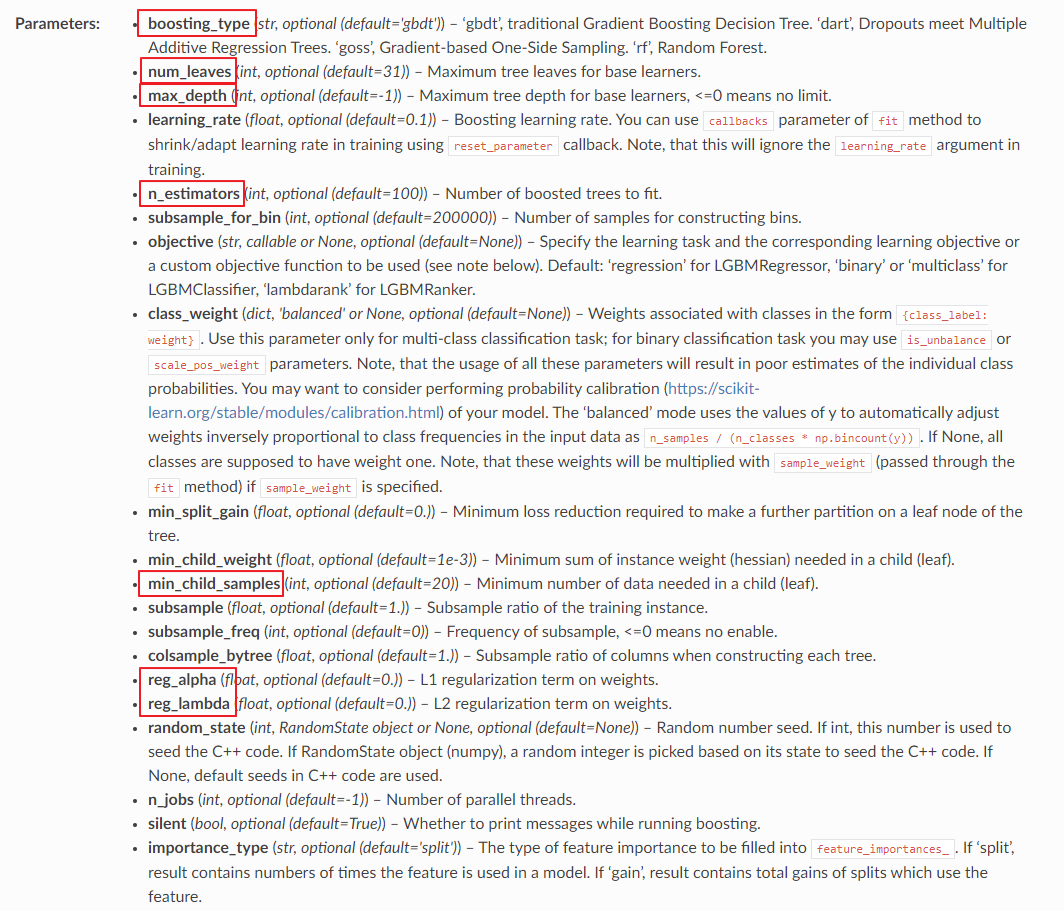
- boosting_type : [ default=’gbdt’ ] 부스팅 트리를 생성하는 알고리즘. gbdt는 일반적인 GB 결정 트리 알고리즘이며, dart와 goss 방식은 기존의 GB 모델 알고리즘을 개선하기 위해 고안된 방법이다. 여기에 잘 설명되어있음(영어주의). rf는 랜덤 포레스트를 뜻한다.
- num_leaves : [ default=31 ] 하나의 트리가 가질 수 있는 최대 리프 개수
- max_depth : [ default=-1 ] 트리 기반 알고리즘의 max_depth와 같다. LightGBM을 소개하면서, 다른 부스팅 유형과 다르게 리프 노드가 계속 분할되면서 트리의 깊이가 깊어진다고 설명했다. 이를 제어하기 위해 하이퍼 파라미터 값을 tuning 해줄 수 있다.
- n_estimators : [ default=100 ] 반복 수행하려는 트리 개수를 지정. 크게 지정할수록 예측 성능이 높아질 수 있으나, 너무 크게 지정하면 overfitting을 유발한다.
- min_child_samples : [ default=20 ] 최종 결정 클래스인 리프 노드가 되기 위해서 최소한으로 필요한 레코드 수
- reg_alpha / reg_lambda : [ default=0.0 ] 각각 L1 정규화, L2 정규화를 위한 값이다.
위의 하이퍼 파라미터 대부분이 overfitting을 제어하기 위해 조정할 수 있는 값들이다. 다음과 같이 활용할 수 있다.
- 모델 복잡도 제어하기 - num_leaves 개수 조정 (높이면 정확도가 높아지지만, 트리의 깊이가 깊어지고 모델이 복잡해짐)
- Overfitting 제어하기 - min_child_samples 높이고 num_leaves와 max_depth 조정, reg_lambda와 reg_alpha 적용
- 성능 높이기 - learning_rate 작게 하면서 n_estimators 크게 하기 (물론 시간이 오래 걸리고 overfitting될 가능성도 있다 -> 오히려 성능이 저하될 수도 있음)
Source : https://heeya-stupidbutstudying.tistory.com/entry/ML-GBM-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98-%EB%B0%8F-LightGBM-%EC%86%8C%EA%B0%9C-%EA%B8%B0%EB%B3%B8%EA%B5%AC%EC%A1%B0-parameters