3-1. Padding, Stride와 Layer size
Convolutional Layer는 커널을 이용하여 이미지에서 feature를 추출하는 Layer입니다.
이미지는 Convolutional Layer를 통과할 때 padding을 따로 추가하지 않았다면 사이즈가 점점 줄어듭니다. 따라서 이를 방지하고자 이미지의 테두리에 padding을 추가하게 됩니다.
그 외에도 Convolutional Layer에서 조절할 수 있는 hyperparameter로는 커널의 개수, 커널의 크기, stride 등이 있습니다. 이들 모두 결과 이미지의 크기와 형태에 영향을 미치기 때문에 이들을 설정했을 때 결과 feature map이 어떻게 변할지 아는 것이 모델 구성의 첫걸음입니다.
이번 실습에서는 다양한 형태의 Convoltuional Layer를 Tensorflow를 통해 구현해보도록 하겠습니다.
지시사항
-
layers.Conv2D하나로 이루어진 모델을 만드는
build_model1함수를 완성하세요. Layer 설정은 아래와 같습니다.
- 커널 개수:
1개 - 커널 크기:
(3, 3) - strides:
(1, 1) - padding:
"same"
- 커널 개수:
-
layers.Conv2D두개로 이루어진 모델을 만드는
build_model2함수를 완성하세요. 두 Layer 모두 아래와 같이 설정하세요.
- 커널 개수:
4개 - 커널 크기:
(3, 3) - strides:
(1, 1) - padding:
"same"
- 커널 개수:
-
layers.Conv2D세개로 이루어진 모델을 만드는
build_model3함수를 완성하세요. Layer 모두에 적용할 설정과 각 Layer 별 설정은 아래와 같습니다.
- 공통 사항
- 커널 크기:
(3, 3) - strides:
(1, 1)
- 커널 크기:
- 첫번째 Layer
- 커널 개수:
2개 - padding:
"same"
- 커널 개수:
- 두번째 Layer
- 커널 개수:
4개 - padding:
"same"
- 커널 개수:
- 세번째 Layer
- 커널 개수:
8개 - padding은 따로 추가하지 않습니다.
- 커널 개수:
- 공통 사항
모델이 잘 완성되었는지 확인하기 위해 가상의 이미지 텐서를 하나 만들어 모델을 통과한 크기가 어떻게 될지 확인할 수 있도록 코드가 완성되어 있습니다. 모델을 모두 구현 후 실행을 통해 확인해보세요.
3-2. MLP로 이미지 데이터 학습하기
이번 실습에서는 Fully-connected Layer를 쌓아 만든 Multilayer Perceptron(MLP) 모델을 사용하여 이미지 데이터를 학습해보도록 하겠습니다.
앞서 이미지 데이터 과목에서 개와 고양이 데이터셋을 통해 실습을 진행했었습니다. 이번 실습부터는 실제 논문에서도 모델 검증을 위해 자주 사용하는 데이터셋인 CIFAR-10 데이터셋을 사용할 것입니다.

CIFAR-10 데이터셋은 각 데이터가 32 ×× 32의 크기를 가지는 컬러 이미지로 구성되어 있습니다. 학습(Train) 데이터셋은 50000개, 테스트(Test) 데이터셋은 10000개의 이미지가 포함되어 있습니다. 각 이미지는 위의 그림에서처럼 10개의 클래스 중 하나에 속합니다.
본 실습에서는 학습 데이터로 50000개와 테스트 데이터로 10000개를 모두 사용하기에는 제약이 있어 각각 7500개와 500개만 가져와 모델을 학습시키고 테스트해볼 것입니다.
지시사항
이번 실습에서는 CIFAR-10의 학습 데이터셋에서 7500개의 이미지와 테스트 데이터셋에서 500개의 이미지를 따로 뽑아내어 numpy array 파일(.npy 파일)로 구성하여 dataset 폴더 내에 저장되어 있습니다.
따라서 데이터를 불러오기 위해 별도로 ImageDataGenerator를 쓰지 않고, load_cifar10_dastaset 함수에서 바로 이 numpy array를 불러오도록 구현되어 있습니다.
numpy array는 그 자체로 바로 tensorflow의 fit 함수에 사용할 수 있습니다. 이 점 참고하여 코드를 완성하세요.
-
MLP 모델을 구성하는 함수
build_mlp_model을 완성하세요.
-
MLP 모델이므로 2차원 이미지를 1차원으로 변형해야 합니다. 맨 먼저
layers.FlattenLayer를 추가하세요. -
이후 마지막을 제외한 각
layers.DenseLayer의 노드 개수는 아래와 같습니다. 모두 활성화 함수는
ReLU
로 설정하세요.
4096개1024개256개64개
-
마지막 Layer는 활성화 함수가 Softmax이고 노드 개수는
num_classes개인layers.DenseLayer입니다.
-
-
main함수에서optimizer는 Adam으로 설정하세요. Learning rate은0.001로 설정하세요. - 모델의 손실 함수와 평가 지표(metrics)를 아래와 같이 설정하세요. optimizer는 2번에서 불러온 것을 사용합니다.
- 손실 함수:
sparse_categorical_crossentropy - 평가 지표(metrics):
"accuracy"
- 손실 함수:
- 모델 학습을 위한 hyperparameter는 아래와 같이 설정하세요.
epochs=epochsbatch_size=64validation_split=0.2shuffle=Trueverbose=2
3-3. MLP와 CNN 모델 비교
이번 실습에서는 앞선 실습에서 CNN 모델을 추가하여 둘의 성능을 비교해보도록 하겠습니다. 데이터셋은 동일한 CIFAR-10 데이터셋을 사용하도록 하겠습니다.
이번 실습에서는 두 모델의 성능을 비교하기 위해 모델이 가지는 파라미터의 개수를 확인하는 코드가 추가되어 있습니다. Tensorflow에서는 아래와 같이 모델에 summary 함수를 실행하면 모델이 가지는 파라미터 개수를 확인할 수 있습니다.
cnn_model.summary()
Copy
출력 예시
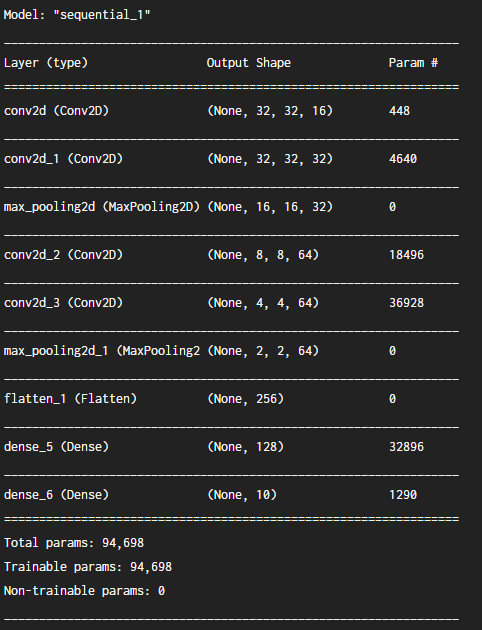
여기서 가장 하단에 나오는 Trainable params의 개수가 실제 모델 학습에 사용되는 파라미터의 개수입니다. MLP와 CNN 모델이 각각 이 값이 어떻게 나오는지 확인해보고, 최종 학습 성능과 테스트 성능이 어떻게 나오는지도 비교해보세요.
지시사항
-
MLP 모델을 구성하는 함수
build_mlp_model을 완성하세요. 앞선 실습과 동일한 값으로 설정하면 됩니다.
-
MLP 모델이므로 2차원 이미지를 1차원으로 변형해야 합니다. 맨 먼저
FlattenLayer를 추가하세요. -
이후 마지막을 제외한 각
DenseLayer의 노드 개수는 아래와 같습니다. 모두 활성화 함수는
ReLU
로 설정하세요.
4096개1024개256개64개
-
마지막 Layer는 활성화 함수가 Softmax이고 노드 개수는
num_classes개인DenseLayer입니다.
-
-
CNN 모델을 구성하는 함수
build_cnn_model을 완성하세요. 모델 Layer 구성은 아래와 같습니다. 모든
Conv2DLayer의 활성화 함수는 ReLU로 설정하세요.
-
layers.Conv2D- 커널 개수:
16개 - 커널 크기:
(3, 3) - padding:
"same" input_shape=img_shape
- 커널 개수:
-
layers.Conv2D- 커널 개수:
32개 - 커널 크기:
(3, 3) - padding:
"same"
- 커널 개수:
-
layers.MaxPool2D- 이미지 사이즈가 2배로 줄도록 설정하세요.
-
layers.Conv2D- 커널 개수:
64개 - 커널 크기:
(3, 3) - padding:
"same" - strides:
(2, 2)
- 커널 개수:
-
layers.Conv2D- 커널 개수:
64개 - 커널 크기:
(3, 3) - padding:
"same" - strides:
(2, 2)
- 커널 개수:
-
layers.MaxPool2D- 이미지 사이즈가 2배로 줄도록 설정하세요.
-
layers.Flatten -
layers.Dense- 노드 개수:
128개 - 활성화 함수: ReLU
- 노드 개수:
-
layers.Dense- 노드 개수:
num_classes - 활성화 함수: Softmax
- 노드 개수:
-
-
run_model함수에서optimizer는 Adam으로 설정하세요. Learning rate은0.001로 설정하세요. -
run_model함수에서 모델의 손실 함수와 평가 지표(metrics)를 아래와 같이 설정하세요. optimizer는 2번에서 불러온 것을 사용합니다.
- 손실 함수:
sparse_categorical_crossentropy - 평가 지표(metrics):
"accuracy"
- 손실 함수:
-
run_model함수에서 모델 학습을 위한 hyperparameter를 아래와 같이 설정하세요.
epochs=epochsbatch_size=64validation_split=0.2shuffle=Trueverbose=2
3-4. VGG16 모델 구현하기
VGGNet은 2014년 ImageNet Challenged에서 2등을 차지한 모델입니다. VGGNet의 의의는 모든 커널의 크기를 3 ×× 3으로 고정하여 본격적으로 CNN 모델의 Layer 개수를 늘리기 시작했다는 것에 있습니다.
VGGNet은 기존 AlexNet의 Layer 개수보다 두배 이상 늘어난 16개와 19개의 두가지 모델이 있습니다. 이번 실습에서는 이 중에서 16개로 이루어진 VGGNet, 즉 VGG16 모델을 구현하도록 하겠습니다.
지시사항
VGGNet부터는 Layer 개수가 많이 늘어남에 따라 Block 단위로 모델을 구성하게 됩니다. 각 Block은 2개 혹은 3개의 Convolutional Layer와 Max Pooling Layer로 구성되어 있습니다.
지시사항에 따라 build_vgg16 함수 내의 각 Block들을 완성하세요.다만 채점은 앞선 실습과 달리 지시사항 별로 확인하는 것이 아닌 전체 모델의 Layer가 올바르게 구성되었는지를 보고 이루어지게 됩니다.
-
첫번째 Block을 완성하세요. Layer 구성은 아래와 같습니다.
-
두개
의
layers.Conv2D- 커널 개수:
64개 - 커널 크기:
(3, 3) - padding:
"same" - 활성화 함수:
ReLU
- 커널 개수:
-
layers.MaxPooling2D: 이미지 사이즈가 2배로 줄어들도록 하세요.
-
-
두번째 Block을 완성하세요. Layer 구성은 아래와 같습니다.
-
두개
의
layers.Conv2D- 커널 개수:
128개 - 커널 크기:
(3, 3) - padding:
"same" - 활성화 함수:
ReLU
- 커널 개수:
-
layers.MaxPooling2D: 이미지 사이즈가 2배로 줄어들도록 하세요.
-
-
세번째 Block을 완성하세요. Layer 구성은 아래와 같습니다.
-
세개
의
layers.Conv2D- 커널 개수:
256개 - 커널 크기:
(3, 3) - padding:
"same" - 활성화 함수:
ReLU
- 커널 개수:
-
layers.MaxPooling2D: 이미지 사이즈가 2배로 줄어들도록 하세요.
-
-
네번째 Block을 완성하세요. Layer 구성은 아래와 같습니다.
-
세개
의
layers.Conv2D- 커널 개수:
512개 - 커널 크기:
(3, 3) - padding:
"same" - 활성화 함수:
ReLU
- 커널 개수:
-
layers.MaxPooling2D: 이미지 사이즈가 2배로 줄어들도록 하세요.
-
-
다섯번째 Block을 완성하세요. Layer 구성은 네번째 Block과 완전히 동일합니다.
모델을 모두 구현하면 모델의 Layer를 확인하기 위한 summary 함수를 실행합니다. 출력 결과를 보고 지시사항의 Layer와 동일한지 확인해보세요.
3-5. ResNet 구현하기
ResNet에 처음 소개된 Residual Connection은 모델 내의 지름길을 새로 만든다고도 하여 Skip Connection이라고도 불리며, 레이어 개수가 매우 많은 경우에 발생할 수 있는 기울기 소실(Vanishing Gradient) 문제를 해결하고자 등장하였습니다.
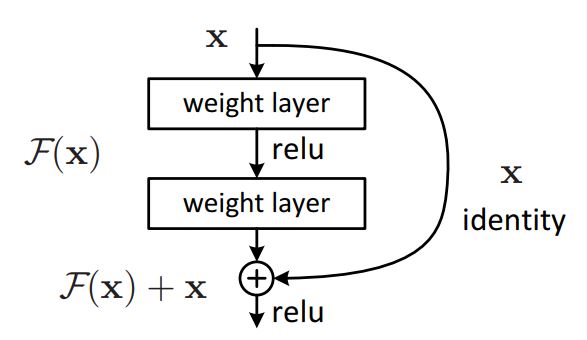
이번 실습에서는 위 그림과 유사한 Residual Connection을 구현해보도록 하겠습니다.
지시사항
Residual Connection은 보통 ResNet의 각 Block 단위로 들어가 있습니다. 따라서 일반적으로 Residual Connection을 가지는 부분을 Residual Block이라 하여 Block 단위로 구현한 후에 이들을 연결하는 식으로 모듈화 하여 전체 모델을 구현하게 됩니다.
Residual Block은 ResidualBlock 이란 이름의 클래스로 현재 스켈레톤이 구현되어 있습니다. 지시사항에 맞춰 클래스 내부를 채워 Residual Block을 완성하세요.
-
ResidualBlock클래스를 완성하세요.
-
두개
의
layers.Conv2DLayer
- 커널 개수:
num_kernels - 커널 크기:
kernel_size - padding:
"same" - 활성화 함수:
ReLU
- 커널 개수:
-
두 텐서를 더하는
layers.AddLayer
-
Residual Block을 완성했다면 이를 활용하는 간단한 ResNet 모델이 build_resnet 함수를 통해 만들어집니다. model.summary() 결과를 통해 Residual Block이 어떻게 모델에 들어가게 되는지 확인해보세요.