-
-
교차 검증이란?
-
보통은 train set 으로 모델을 훈련, test set으로 모델을 검증한다.
-
여기에는 한 가지 약점이 존재한다.
-
고정된 test set을 통해 모델의 성능을 검증하고 수정하는 과정을 반복하면, 결국 내가 만든 모델은 test set 에만 잘 동작하는 모델이 된다.
-
즉, test set에 과적합(overfitting)하게 되므로, 다른 실제 데이터를 가져와 예측을 수행하면 엉망인 결과가 나와버리게 된다.
-
이를 해결하고자 하는 것이 바로
교차 검증(cross validation)
이다.
- 교차 검증은 train set을 train set + validation set으로 분리한 뒤, validation set을 사용해 검증하는 방식이다.
교차 검증의 장점과 단점
- 장점
- 모든 데이터셋을 훈련에 활용할 수 있다.
- 정확도를 향상시킬 수 있다.
- 데이터 부족으로 인한 underfitting을 방지할 수 있다.
- 모든 데이터셋을 평가에 활용할 수 있다.
- 평가에 사용되는 데이터 편중을 막을 수 있다.
- 평가 결과에 따라 좀 더 일반화된 모델을 만들 수 있다.
- 모든 데이터셋을 훈련에 활용할 수 있다.
- 단점
- Iteration 횟수가 많기 때문에, 모델 훈련/평가 시간이 오래 걸린다.
교차 검증 기법 종류
- K-Fold Cross Validation ( k-겹 교차 검증 )
- Stratified K-Fold Cross Validation ( 계층별 k-겹 교차 검증 )
- 등
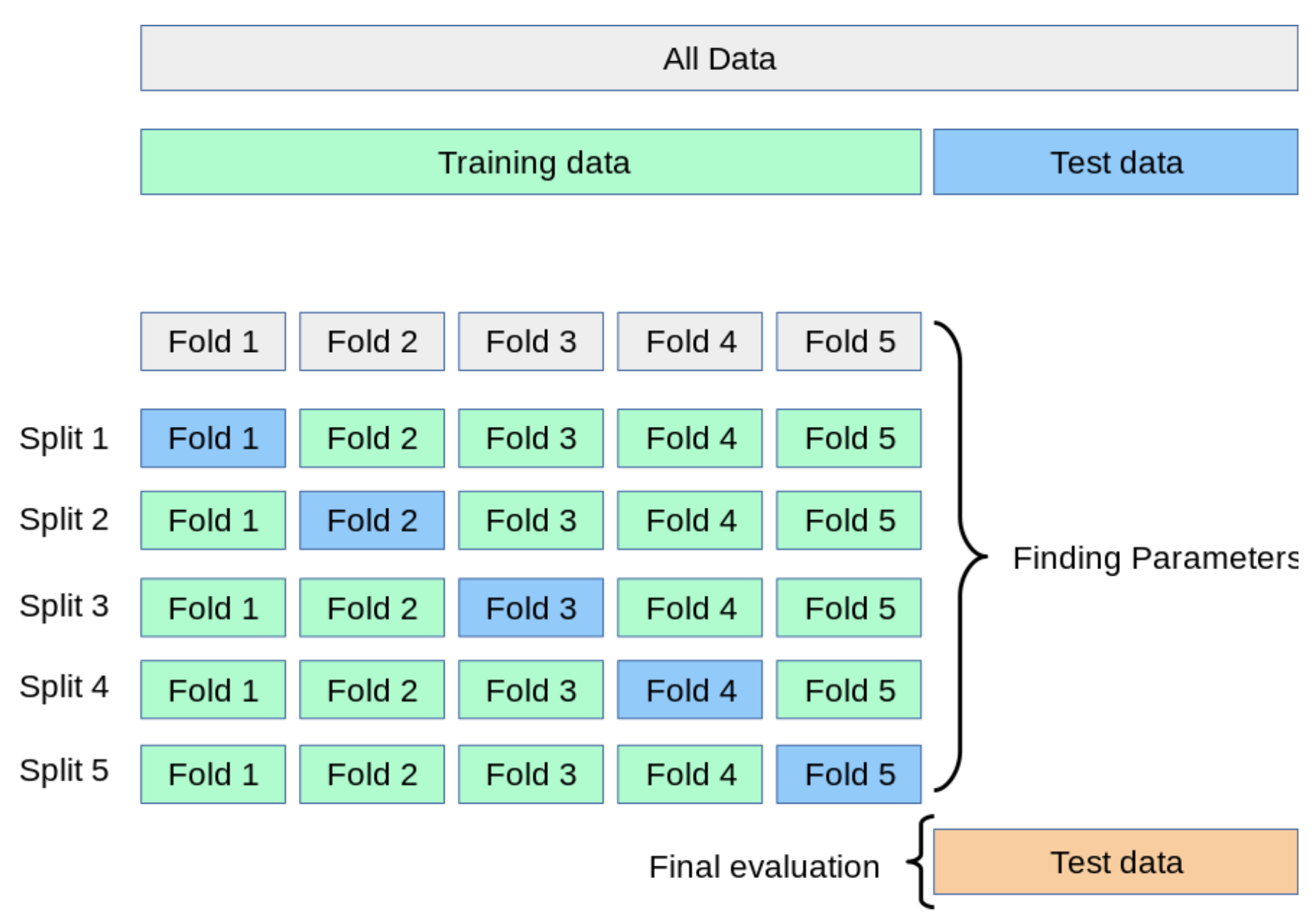
K-Fold Cross Validation ( k-겹 교차 검증 )
-
K-Fold는 가장 일반적으로 사용되는 교차 검증 방법이다.
-
보통 회귀 모델에 사용되며, 데이터가 독립적이고 동일한 분포를 가진 경우에 사용된다.
-
자세한 K-Fold 교차 검증 과정은 다음과 같다.
- 전체 데이터셋을 Training Set과 Test Set으로 나눈다.
- Training Set를 Traing Set + Validation Set으로 사용하기 위해 k개의 폴드로 나눈다.
- 첫 번째 폴드를 Validation Set으로 사용하고 나머지 폴드들을 Training Set으로 사용한다.
- 모델을 Training한 뒤, 첫 번 째 Validation Set으로 평가한다.
- 차례대로 다음 폴드를 Validation Set으로 사용하며 3번을 반복한다.
- 총 k 개의 성능 결과가 나오며, 이 k개의 평균을 해당 학습 모델의 성능이라고 한다.
-
예제 코드
-
sklearn에서는 교차검증을 위해 cross_val_score 함수를 제공한다.
from sklearn.datasets import load_iris from sklearn.model_selection import cross_val_score iris_data = load_iris() # 모델 logreg = LogisticRegression() # 파라미터는 (모델, Traingdata의 feature, Trainingdata의 target, 폴드수) 이다. scores = cross_val_score(logreg , iris.data , iris.target ,cv=3) # Trainingdata에 대한 성능을 나타낸다. print('교차 검증별 정확도:',np.round(scores, 4)) print('평균 검증 정확도:', np.round(np.mean(scores), 4)) -
KFold 상세 조정
-
위 cross_val_score 함수에서는, cv로 폴드의 수를 조정할 수 있었다.
-
만약 검증함수의 매개변수를 디테일하게 제어하고 싶다면
-
따로 검증함수 객체를 만들고 매개변수를 조정한 다음, 해당 객체를 cross_val_score의 cv 매개변수에 넣을 수도 있다.
-
이를 ‘교차 검증 분할기’ 라고도 한다.
from sklearn.datasets import load_iris from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score iris_data = load_iris() # 모델 logreg = LogisticRegression() # n_split : 몇개로 분할할지 # shuffle : Fold를 나누기 전에 무작위로 섞을지 # random_state : 나눈 Fold를 그대로 사용할지 kfold = KFold(n_splits=6, shuffle = True, random_state=0) # 파라미터는 (모델, Traingdata의 feature, Trainingdata의 target, 폴드수) 이다. scores = cross_val_score(logreg , iris.data , iris.target ,cv=kfold) # Trainingdata에 대한 성능을 나타낸다. print('교차 검증별 정확도:',np.round(scores, 4)) print('평균 검증 정확도:', np.round(np.mean(scores), 4))Source : https://wooono.tistory.com/105
-
-
-
-